
Reject inference in credit scoring refers to the process of estimating the creditworthiness of applicants who have been rejected for loans or credit based on the available data from approved applicants. It aims to overcome the limitation of using only past loan data by incorporating information from rejected applications to create a more comprehensive credit scoring model. Simply put, the reject inference involves thinking why the loans were rejected and comparing them to those that were accepted, this helps improve the decisions that are made overall.
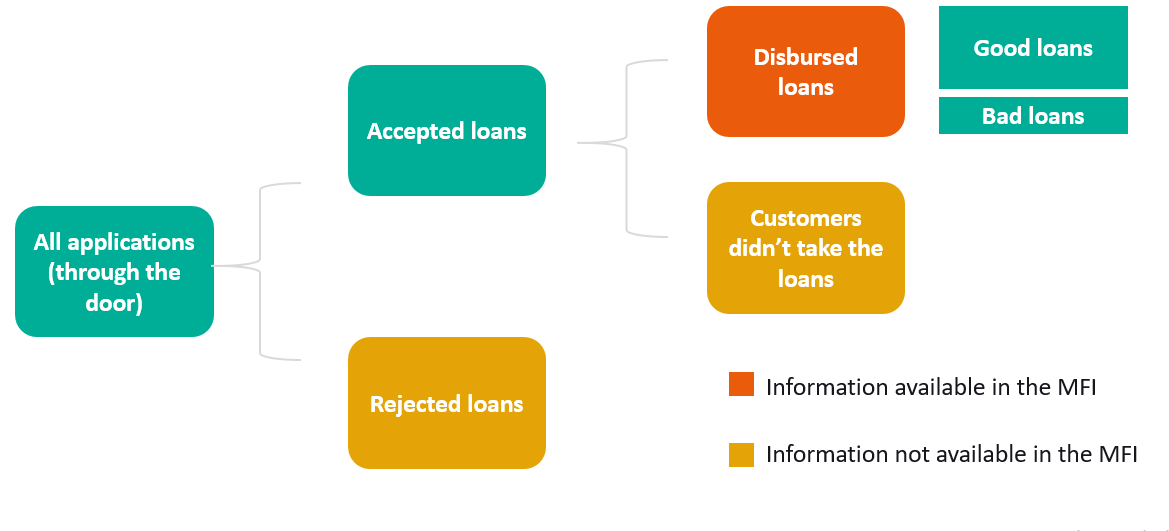
Reject inference is particularly relevant in the context of microfinance institutions (MFIs) where rejection rates tend to be higher, loan amounts are lower, and default rates are also higher compared to traditional lending. In these cases, the exclusion of rejected applicants from the credit scoring process can lead to biased results and inaccurate risk assessments.
To address this issue, various methods are commonly used in research and practice. Many microfinance institutions use the below approaches but this could be done more comprehensively and systematically.
- Credit Reference Bureaus: Access to credit reference bureaus can provide additional data on rejected applicants, including their credit histories, outstanding debts, and payment behavior with other lenders. Incorporating this information into the credit scoring model can enhance its predictive accuracy.
- Augmentation: Augmentation involves augmenting the existing approved applicant data with ‘synthetic’ rejected applicants. These synthetic applicants are created using statistical techniques to simulate the characteristics and behaviors of the rejected population. By blending the approved and synthetic data, a more representative credit scoring model can be developed.
- Extrapolation: Extrapolation techniques involve extrapolating the relationship between observed variables in the approved applicant data and the likelihood of default. This extrapolation is then applied to the rejected applicant data to estimate their default probabilities. This approach assumes that the relationships observed in the approved data hold true for the rejected population as well.
It’s important to note that each method has its own limitations and considerations. The effectiveness of reject inference depends on the underlying assumptions and the representativeness of the available data. Therefore, it is crucial to carefully analyze the data, validate the assumptions, and assess the performance of the credit scoring model when applying reject inference techniques.
In L-IFT we have groups of respondents with a loan history and those without a loan history collected using our FINBIT app. Those with past loan histories have information on their payment and can be used for credit scoring. We treat those without any loan history as ‘rejected’ loans and analyze their information in comparison with those that had loans thereby improving our understanding of the credit scoring process. Our aim is to ensure even those without credit histories access loans using their diaries data on FINBIT. For this, we are pioneering risk-based loan pricing as part of our credit appraisal instead of a binary ‘reject’ and ‘accept’ approach to credit scoring. What this means is that people with low credit scores can get higher-interest loans to offset the risk, while those with high credit scores can get lower-interest loans but the key thing is that everyone gets financing, and they can improve their credit scores over time, and make the loan offerings cheaper.
Overall, reject inference can contribute to improving the performance of credit scoring systems, especially in the context of MFIs where the inclusion of rejected applicants becomes essential for more accurate risk assessments and better financial inclusion.